AI Content Creation Assistant — Part 3: WebSockets & Persistent Storage


Welcome to part 3 of this series. In the previous post, we adapted our Jupyter Notebook implementation from part 1 into a FastAPI server that can serve users. We learned how to set up FastAPI and configure settings, as well as how to trigger workflows from REST endpoints.
Previously, we identified some limitations in our solution. Users will have to wait for the response after the workflow is completed. We have also been saving our content in a local folder. While this is okay for quick experimenting, we will expand this solution to send progress events and use an appropriate storage mechanism in this post.
In addition to improving our solution, we will continue to abstract our code into succinct modules and pin our dependencies to ensure build reproducibility.
Series
- AI Content Creation Assistant — Part 1: GenAI Workflows
- AI Content Creation Assistant — Part 2: FastAPI
- AI Content Creation Assistant – Part 3: WebSockets and Persistent Storage
- AI Content Creation Assistant – Part 4: User Interface
- AI Content Creation Assistant - Part 5: Deployment
What to expect
- Stream progress events to users throughout a workflow
- How to use SQLAlchemy ORM to interact with Postgres
- Running migrations with Alembic
- Saving images to Minio
- Run multiple Docker applications together with Docker-Compose
- Configure the WebSocket endpoint in the FastAPI application
Here's the final product from part 3 changes. (Postman client used)

Code Structure
├── README.md
├── alembic
│ ├── README
│ ├── env.py
│ ├── script.py.mako
│ └── versions
├── alembic.ini
├── docker-compose.yml
├── infrastructure
│ └── init-db.sh
├── pyproject.toml
├── requirements
│ ├── requirements-dev.txt
│ └── requirements.txt
└── src
├── content
│ ├── api.py
│ ├── models
│ ├── prompts
│ ├── repositories
│ ├── schemas
│ ├── services
│ └── workflows
├── core
│ ├── api.py
│ ├── database.py
│ ├── logs.py
│ └── middleware.py
├── main.py
└── settings
└── config.pyCompared to the previous post, the overall structure of our projects has expanded. We have a few top-level directories:
- Alembic—We will discuss this more in the SQLAlchemy section below, but this directory contains our database migrations. A migration essentially changes the structure of the database. These files are auto-generated, and we only need to modify
env.pyandalembic.ini.- Alembic.ini is an auto-generated related config file. We only need to remove one line from it, as most of the configuration is set up in
env.py
- Alembic.ini is an auto-generated related config file. We only need to remove one line from it, as most of the configuration is set up in
docker-compose.ymlcontains configuration to run Postgres and Minio in containers on the same network with provisioned storage using volumes- Infrastructure: Our database models use UUIDs for GUIDS. This directory contains a script to enable the
uuid.osspextension the first time Postgres runs Pyproject.tomlis a configuration file for packaging-related tools.- Requirements: This holds our production and development dependencies pinned by version. The setting up dependencies section provides more on this.
Source Directory
The source directory contains the bulk of the source code. The code is structured around domains consisting of core and content. The core domain includes files that impact the server holistically (middleware) or contain logic to be used in other domains, such as database sessions, logging function, and a health check for later k8s deployment. The content domain uses DDD tactical patterns: Repository and Services to cleanly abstract code. Each domain (next up will be users) will follow the same general structure:
- Models: SQLAlchemy models that define the database schema.
- Schema: Pydantic models which handle input and output data validation and serialization.
- Repositories: The repositories are responsible for data access. Separating data access logic, ensuring easier testing and maintenance.
- Services: coordinates business logic, interfacing between application logic and data access logic (repository)
Content domain specifically has:
- Prompts: a central place to store prompts. For now, other tools later in the series will address prompt versioning and a more robust approach.
- Workflows: stores all workflows.
Dependencies Setup
In part 2, we set up our virtual environment using Conda and installed all our dependencies through the command line. This works initially, but the underlying dependencies can change, breaking the source code. In this project, we introduce pyproject.toml, which has become the de facto standard for configuring Python applications.
[build-system]
requires = ["setuptools", "wheel"]
build-backend = "setuptools.build_meta"
[project]
name = "content_assistant"
authors = [{ name = "Markell Richards" }]
version = "0.0.1"
requires-python = ">=3.12"
readme = "README.md"
dependencies = [
"fastapi",
"uvicorn[standard]",
"tenacity",
"asyncio",
"llama-index-core",
"llama-index-llms-openai",
"tavily-python",
"openai",
"pydantic-settings",
"minio",
"JSON-log-formatter",
"sqlalchemy",
"alembic",
"psycopg2-binary",
"boto3",
"asyncpg",
]
[project.optional-dependencies]
dev = ["ruff", "black"]With our application metadata and dependencies defined, we need to create a requirements.txt for pip to install. We will use pip-tools which consist of pip-compile and pip-sync. pip-compile pins the dependencies so pip knows how to resolve them and which versions to install. Great dependency management revolves around dependency resolving and dependency locking. These two concepts allow us to have deterministic builds. Ensuring the app is built the same regardless of where and when.
To generate the hashes and lock versions, we use the following commands:
pip-compile --generate-hashes -o requirements/requirements.txt pyproject.toml
pip-compile --extra dev -o requirements/requirements-dev.txt pyproject.tomlWe use requirements-dev for local development as it will include additional dependencies defined in the dev section of our pyproject.toml. These aren't needed for the production build and are excluded from requirements.txt.
To install the dependencies, we use:
pip-sync requirements/requirements.txt requirements/requirements-dev.txtpip-sync installs dependencies based on the output of our pip-compile.
APIs
Each domain has its own api.py with a set of routes. These are defined as routers and are included in our main.py, as shown here:
app = FastAPI(version=version)
app.include_router(core_router)
app.include_router(content_router)Core router
In part 6 of this series, we will deploy our full-stack application to Kubernetes. Typically, the containers in Kubernetes pods should have a way to check the health of an application. More on this will be covered later, but for now, we defined a simple health check endpoint that returns the version of our API (version is specified in pyproject.toml):
from fastapi import APIRouter, status
from fastapi.requests import Request
router = APIRouter(tags=["Core Endpoints"])
@router.get("/health", status_code=status.HTTP_200_OK)
async def healthcheck(request: Request) -> dict:
return {"version": request.app.version}Content Router
We establish a WebSocket connection to provide users with real-time updates as a workflow proceeds through its steps.
router = APIRouter(tags=["Content Endpoints"])
@router.websocket("/content")
async def advancedContentFlow(websocket: WebSocket, db: Session = Depends(get_db), settings: Settings = Depends(get_settings)):
await websocket.accept()
s3_client = boto3.client(
's3',
endpoint_url=settings.MINIO_ENDPOINT,
aws_access_key_id=settings.AWS_ACCESS_KEY_ID,
aws_secret_access_key=settings.AWS_SECRET_ACCESS_KEY,
region_name='us-east-1',
# Disable SSL verification if using HTTP
config=boto3.session.Config(signature_version='s3v4')
)
workflow_repository = WorkflowRepository(db)
blog_repository = BlogRepository(db)
social_media_repository = SocialMediaRepository(db)
image_repository = ImageRepository(db)
workfow_service = WorkflowService(workflow_repository)
blog_service = BlogService(blog_repository)
social_media_service = SocialMediaService(social_media_repository)
image_service = ImageService(image_repository=image_repository, s3_client=s3_client)
workflow = AdvancedWorkflow(settings, db, workfow_service=workfow_service, blog_service=blog_service,
social_media_service=social_media_service, image_service=image_service)
try:
data = await websocket.receive_json()
logger.info(data)
handler: WorkflowHandler = workflow.run(topic=data["topic"], research=data["research"])
async for event in handler.stream_events():
if isinstance(event, ProgressEvent):
await websocket.send_json({
"type": "progress_event",
"payload": str(event.msg)
})
result = await handler
await websocket.send_json({
"type": "results",
"payload": result
})
except Exception as e:
await db.rollback()
await websocket.send_json({
"type": "error",
"payload": "Something went wrong"
})
logger.error(e)
finally:
await websocket.close()Stepping through the code:
- Using dependency injection, we inject a database session and settings object into each connection.
- Accept an incoming WebSocket connection.
- Minio is an S3 Compatible object storage. We use the AWS boto SDK to interact with Minio. We create an
s3_clientto pass into ourimage_servicewhich contains the logic to upload images. - We create instances of each repository and service type: workflow, blog, social media, and image.
- We create an instance of AdvanceWorkflow and pass in settings, db session, and every service.
- We accept a JSON payload containing a content topic and research boolean flag.
- We run our workflow and listen for
ProgressEvent. As the workflow progresses, each step will publish aProgressEventwith amsgthat will be sent to the client. - Once the workflow finishes, the user gets a result payload signifying the workflow as completed or failed.
- Error handling in the event something goes wrong
- Finally, we close the WebSocket connection.
SqlAlchemy and Alembic
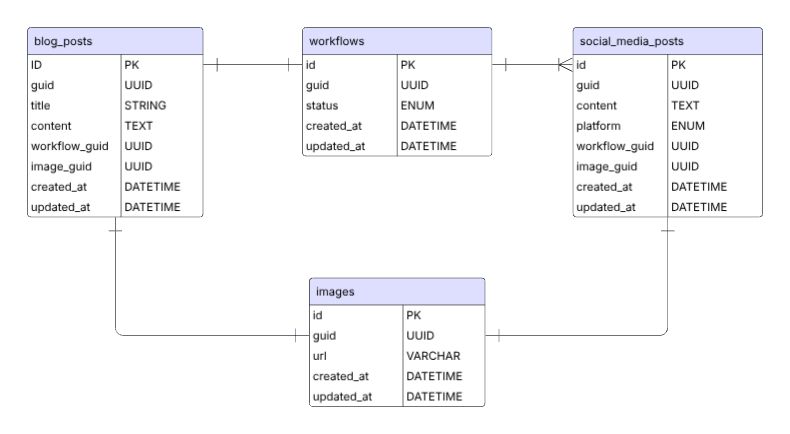
As mentioned, we added Postgres and Minio to the project to persist in storing entities created throughout the workflows for later retrieval. Above is a simple entity relationship diagram (ERD) of how the tables map together. This is subject to change, but at this point, this structure gives us some general access patterns:
- Each blog and social media post belongs to one workflow. If we fetch a workflow, we can grab all related entities.
- In a single workflow, blog and social media posts share the same image generated. However, later, the user can change the media used through the interface.
- A user can edit the content of blog and social media post in later enhancements.
To facilitate the interaction with the database and management of its structure, we use SqlAlchemy and Alembic. SQLAlchemy is an object-relational mapper (ORM) that helps you interact with databases using Python. It offers various patterns that make managing data easier and more efficient. SQLAlchemy is designed for high performance, allowing quick access to database information using simple and clear Python.
Alembic is a lightweight database migration tool built to be used with SqlAlchemy. It performs "migrations" to change the structure of the database. By change, this includes adding tables, updating models, etc.
Each SqlAlchemy model follows the same pattern so I will show just one example. See the source code for the rest of the entities.
import uuid
from src.core.database import Base
from sqlalchemy.dialects.postgresql import UUID
from sqlalchemy import types, ForeignKey, func, DateTime, Column
from sqlalchemy.orm import relationship
class BlogPosts(Base):
__tablename__ = 'blog_posts'
id = Column(types.INTEGER, primary_key=True, autoincrement=True)
guid = Column(UUID(as_uuid=True),
primary_key=False,
unique=True,
nullable=False,
server_default=func.uuid_generate_v4(),
default=uuid.uuid4)
title = Column(types.String)
content = Column(types.TEXT)
created_at = Column(DateTime, default=func.now(), nullable=False)
updated_at = Column(DateTime, default=func.now(), onupdate=func.now(), nullable=False)
workflow_guid = Column(ForeignKey("workflows.guid"))
image_guid = Column(ForeignKey("images.guid"))
image = relationship("Images")Here, we define our blog_posts table, which is shown in the ERD. We define each column and its associated type. Postgres' built-in function uuid_generate_v4() generates a unique identifier for the guid column. func.now generates the timestamp for created_at and updated_at columns. Then define our workflow and image relationships using ForeignKey. Lastly, we use the relationship module to allow easy access to images related to a blog post using the ORM.
To use the uuid_generate_v4() function with Postgres, we must ensure the extension is enabled in our database.
set -e
psql -v ON_ERROR_STOP=1 --username "$POSTGRES_USER" --dbname "$POSTGRES_DB" <<-EOSQL
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
EOSQLThis script is passed into our docker instance running Postgres and will enable the extension.
Now that our model is defined and extension is configured, lets create a migration.
In the root directory, you'll run the following command:
alembic init alembicThis will generate the following files:
- /versions directory: contains each migration generated
- env.py: used to configure alembic
- README.md: generic information from alembic
- script.py.mako
- alembic.ini
After these files are generated, we need to modify alembic.ini and env.py. In alembic.ini, remove the following line:
sqlalchemy.url =Next, we modify a few lines in env.py:
## import necessary source code
from src.core.database import Base
from src.settings.config import Settings
from src.content.models.workflows import Workflow
from src.content.models.blog_posts import BlogPosts
from src.content.models.social_media_post import SocialMediaPosts
from src.content.models.images import Images
# alembic generated code
target_metadata = Base.metadata
settings = Settings()
config.set_main_option("sqlalchemy.url", settings.DATABASE_URL)
# rest of alembic generated code
The models must be imported into this file for the migrations to run. We also import Base from our database.py
from sqlalchemy.ext.asyncio import create_async_engine, AsyncSession
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from src.core.logs import logger
from src.settings import settings
Base = declarative_base()
# for alembic
sync_engine = create_engine(settings.DATABASE_URL, echo=True)
async_engine = create_async_engine(settings.ASYNC_DATABASE_URL, echo=True, future=True)
AsyncSessionFactory = sessionmaker(
bind=async_engine,
class_=AsyncSession,
expire_on_commit=False,
autocommit=False,
autoflush=False,
)
async def get_db():
async with AsyncSessionFactory() as session:
yield sessionBase contains the metadata of our models, which each of our SqlALchemy models inherits. Alembic is synchronous by nature compared to FastAPI, which is asynchronous. I defined two database engines to avoid overcomplicating the alembic configuration to be async. One synchronous that uses a different URL is used by Alembic, and FastAPI uses another async URL. Here is an example of their URLs:
ASYNC_DATABASE_URL=postgresql+asyncpg://postgres-user:postgres-pw@localhost:5432/demo # EXAMPLE
DATABASE_URL=postgresql://postgres-user:postgres-pw@localhost:5432/demo #EXAMPLEWith everything configured, we can run the following two commands to generate a migration and update our database:
alembic revision --autogenerate -m "Initial migration"
alembic upgrade head # updates database tables & schemasWorkflow
from llama_index.core.workflow import Workflow, Event, StartEvent, StopEvent, Context, step
from sqlalchemy.orm import Session
from src.content.services.workflow_service import WorkflowService
from src.content.services.blog_service import BlogService
from src.content.services.social_media_service import SocialMediaService
from src.content.services.image_service import ImageService
from src.content.schemas.workflow import WorkflowStatusType, WorkflowCreate, WorkflowUpdate
from src.content.schemas.blog_posts import BlogCreate, BlogUpdate
from src.content.schemas.social_media_post import SocialMediaCreate, PlatformType, SocialMediaUpdate
from src.content.schemas.tavily_search import TavilySearchInput
from src.content.schemas.images import ImageCreate
from src.content.prompts.prompts import *
from src.content.services.tavily_search_service import tavily_search
from llama_index.llms.openai import OpenAI as LlamaOpenAI
from openai import OpenAI
from src.core.logs import logger
class ResearchEvent(Event):
topic: str
research: bool
class BlogEvent(Event):
topic: str
research: bool
research_material: str
class SocialMediaEvent(Event):
blog: str
class SocialMediaCompleteEvent(Event):
pass
class IllustratorEvent(Event):
blog: str
class IllustratorCompleteEvent(Event):
url: str
class ProgressEvent(Event):
msg: str
class RetryEvent(Event):
pass
class WorkflowFailedEvent(Event):
error: str
class AdvancedWorkflow(Workflow):
def __init__(self, settings, db: Session, workfow_service: WorkflowService, blog_service: BlogService, social_media_service: SocialMediaService, image_service: ImageService, timeout=None, verbose=None):
super().__init__(timeout, verbose)
self.settings = settings
self.db = db
self.workflow_service = workfow_service
self.blog_service = blog_service
self.social_media_service = social_media_service
self.image_service = image_service
@step
async def start_event(self, ev: StartEvent, ctx: Context) -> ResearchEvent | BlogEvent | WorkflowFailedEvent:
ctx.write_event_to_stream(ProgressEvent(msg="Starting content creation workflow"))
workflow_data = WorkflowCreate(status=WorkflowStatusType.INPROGRESS)
try:
workflow = await self.workflow_service.create_workflow(workflow_data=workflow_data)
await ctx.set(key="workflow_id", value=workflow.id)
await ctx.set(key="workflow_guid", value=workflow.guid)
if ev.research:
return ResearchEvent(topic=ev.topic, research=ev.research)
return BlogEvent(topic=ev.topic, research=ev.research, research_material="None")
except Exception as e:
return WorkflowFailedEvent(error=f"{e}")
@step
async def research_event(self, ev: ResearchEvent, ctx: Context) -> BlogEvent | WorkflowFailedEvent:
ctx.write_event_to_stream(ProgressEvent(msg=f"Searching internet for information about {ev.topic}"))
try:
search_input = TavilySearchInput(
query=ev.topic,
max_results=3,
search_depth="basic"
)
research_material = await tavily_search(search_input, api_key=self.settings.TAVILY_SEARCH_API_KEY)
return BlogEvent(topic=ev.topic, research= ev.research, research_material=research_material)
except Exception as e:
return WorkflowFailedEvent(error=f"{e}")
@step
async def blog_event(self, ev: BlogEvent, ctx: Context) -> SocialMediaEvent | WorkflowFailedEvent:
ctx.write_event_to_stream(ProgressEvent(msg="Writing blog post"))
prompt_template = ""
workflow_guid = await ctx.get("workflow_guid")
try:
if(ev.research):
prompt_template = BLOG_AND_RESEARCH_TEMPLATE.format(query_str=ev.topic, research=ev.research_material)
else:
prompt_template = BLOG_TEMPLATE.format(query_str=ev.topic)
llm = LlamaOpenAI(model=self.settings.OPENAI_MODEL, api_key=self.settings.OPENAI_API_KEY)
response = await llm.acomplete(prompt_template)
blog_data = BlogCreate(title=ev.topic, content=response.text, workflow_guid=workflow_guid)
blog_post = await self.blog_service.create_blog(blog_data=blog_data)
await ctx.set(key="blog_id", value=blog_post.id)
ctx.send_event(SocialMediaEvent(blog=blog_data.content))
except Exception as e:
return WorkflowFailedEvent(error=f"{e}")
@step
async def social_media_event(self, ev: SocialMediaEvent, ctx: Context) -> SocialMediaCompleteEvent | IllustratorEvent | WorkflowFailedEvent:
ctx.write_event_to_stream(ProgressEvent(msg="Writing social media post"))
worklflow_guid = await ctx.get("workflow_guid")
try:
prompt_template = LINKED_IN_TEMPLATE.format(blog_content=ev.blog)
llm = LlamaOpenAI(model=self.settings.OPENAI_MODEL, api_key=self.settings.OPENAI_API_KEY)
response = await llm.acomplete(prompt_template)
sm_data = SocialMediaCreate(content=response.text, platform_type=PlatformType.LINKEDIN, workflow_guid=worklflow_guid)
sm_post = await self.social_media_service.create_social_media_post(social_media_data=sm_data)
await ctx.set(key="sm_id", value=sm_post.id)
ctx.send_event(IllustratorEvent(blog=ev.blog))
return SocialMediaCompleteEvent()
except Exception as e:
return WorkflowFailedEvent(error=f"{e}")
@step
async def illustration_event(self, ev: IllustratorEvent, ctx: Context) -> IllustratorCompleteEvent | WorkflowFailedEvent:
ctx.write_event_to_stream(ProgressEvent(msg="Drawing illustration for content"))
try:
llm = LlamaOpenAI(model=self.settings.OPENAI_MODEL, api_key=self.settings.OPENAI_API_KEY)
image_prompt_instructions_generator = IMAGE_GENERATION_TEMPLATE.format(blog_post=ev.blog)
image_prompt = await llm.acomplete(image_prompt_instructions_generator, formatted=True)
openai_client = OpenAI(api_key=self.settings.OPENAI_API_KEY)
file_name = await self.image_service.generate_and_upload_image(bucket=self.settings.MINIO_BUCKET_NAME, openai_client=openai_client, image_prompt=image_prompt.text)
url = f"{self.settings.MINIO_ENDPOINT}/{self.settings.MINIO_BUCKET_NAME}/{file_name}"
image_data = ImageCreate(url=url)
image = await self.image_service.create_image(image_data=image_data)
await ctx.set("image_guid", image.guid)
return IllustratorCompleteEvent(url=url)
except Exception as e:
return WorkflowFailedEvent(error=f"{e}")
@step
async def step_workflow_success(self, ev:SocialMediaCompleteEvent | IllustratorCompleteEvent, ctx: Context) -> StopEvent | WorkflowFailedEvent:
if (
ctx.collect_events(
ev,
[SocialMediaCompleteEvent, IllustratorCompleteEvent]
) is None
) : return None
workflow_id = await ctx.get("workflow_id")
image_guid = await ctx.get("image_guid")
blog_id = await ctx.get("blog_id")
sm_id = await ctx.get("sm_id")
workflow_update_data = WorkflowUpdate(id=workflow_id, status=WorkflowStatusType.COMPLETE)
blog_update_data = BlogUpdate(id=blog_id, image_guid=image_guid)
sm_update_data = SocialMediaUpdate(id=sm_id, image_guid=image_guid)
try:
await self.workflow_service.update_workflow(workflow_id, workflow_update_data)
await self.blog_service.update_blog(blog_id=blog_id, blog_data=blog_update_data)
await self.social_media_service.update_social_media_post(sm_id=sm_id, sm_data=sm_update_data)
return StopEvent(result="Done")
except Exception as e:
return WorkflowFailedEvent(error=f"{e}")
@step
async def step_workflow_failed(self, ev: WorkflowFailedEvent, ctx: Context) -> StopEvent:
try:
workflow_id = await ctx.get("workflow_id")
workflow_update_data = WorkflowUpdate(id=workflow_id, status=WorkflowStatusType.FAILED)
await self.workflow_service.update_workflow(workflow_id, workflow_update_data)
return StopEvent(result="Failed")
except:
logger.error(ev.error)
return StopEvent(result="Failed")
Our workflow has mostly stayed the same, except for the addition of using services to handle logic related to managing entities in Postgres and Minio. We also added a failure step in case anything goes wrong. To note, social media workflow is now calling the illustration step. This avoids the same session performing two operations simultaneously, causing a collision. In the future, we can pass in a session factory to enable parallel processing, but I did not for the sake of time.
Services and Repositories
In Domain-Driven Design (DDD), tactical patterns are essential design guidelines that effectively organize and structure code within a bounded context. We implement the repository and service pattern described above in our code base. The patterns are repeatable, so like before, I show one example, in this case for Images, as they include additional logic for generating and uploading images.
First, we define an interface with images that the ImageRepository must implement.
from abc import ABC, abstractmethod
from src.content.schemas.images import ImageCreate, Image
class IImagesRepository(ABC):
@abstractmethod
async def create_image(self, image_data: ImageCreate) -> Image:
passThen we define the ImageRepositoy:
from src.content.repositories.images.images_repository_interface import IImagesRepository
from src.content.schemas.images import Image, ImageCreate
from src.content.models.images import Images
from sqlalchemy.ext.asyncio import AsyncSession
class ImageRepository(IImagesRepository):
def __init__(self, async_db_session: AsyncSession):
self.db = async_db_session
async def create_image(self, image_data) -> Image:
if not isinstance(image_data, ImageCreate):
raise ValueError("Expected instance of ImageCreate")
try:
new_image_data = Images(url=image_data.url)
self.db.add(new_image_data)
await self.db.commit()
await self.db.refresh(new_image_data)
return Image(
id=new_image_data.id,
guid=new_image_data.guid,
url=new_image_data.url
)
except:
await self.db.rollback()
raiseThe interface defined one create_image method. The ImageRepositoy implements this method by checking if the data passed in matches the Pydantic schema ImageCreate. If it is a valid payload, it creates a new Images instance passing in the URL generated from the Minio address upload (see service file). The id, guid, created_at, and updated_at are auto-generated. It then uses the session methods to add and commit the entity to the database. Then, the image is returned to the caller for further processing. In this case, the guid will be used to map the relationship between blog_posts and social_media_posts image_guid fields.
Lastly, we define the ImageService file:
import uuid
import requests
from io import BytesIO
from src.content.repositories.images.images_repository import ImageRepository
from src.content.schemas.images import ImageCreate, Image as ImageSchema
from src.content.models.images import Images
from PIL import Image as PilImage
from botocore.exceptions import NoCredentialsError, ParamValidationError
from tenacity import retry, wait_random_exponential, stop_after_attempt
from openai import OpenAI
from src.core.logs import logger
class ImageService(ImageRepository):
def __init__(self, image_repository: ImageRepository, s3_client):
self.repository = image_repository
self.s3_client = s3_client
async def create_image(self, image_data: ImageCreate) -> ImageSchema:
image = await self.repository.create_image(image_data)
return ImageSchema.model_validate(image)
@retry(wait=wait_random_exponential(min=1, max=15), stop=stop_after_attempt(3))
async def generate_image(self, client: OpenAI, prompt: str):
try:
response = client.images.generate(
model="dall-e-3", # will make configurable in future
prompt=prompt,
size="1024x1024", # will make configurable in future
quality="standard", # will make configurable in future
n=1
)
return response
except:
raise Exception("Failed to generate image")
async def generate_and_upload_image(self, bucket, openai_client: OpenAI, image_prompt):
try:
generated_image = await self.generate_image(client=openai_client, prompt=image_prompt)
image_url = generated_image.data[0].url
response = requests.get(image_url)
image = PilImage.open(BytesIO(response.content))
image_bytes = BytesIO()
image.save(image_bytes, format='PNG')
image_bytes.seek(0)
file_name = f"test_{uuid.uuid4()}.png"
await self.upload_to_minio(bucket, image_bytes.getvalue(), file_name)
return file_name
except:
raise Exception("Failed to upload to minio or create database entry")
async def upload_to_minio(self, bucket, file_data, filename):
try:
self.s3_client.put_object(Bucket=bucket, Key=filename, Body=file_data)
logger.error(msg=f"Uploaded {filename} to MinIO bucket successfully!")
except NoCredentialsError:
logger.error(msg="Credentials not available.")
except ParamValidationError as e:
logger.error(msg=f"Parameter validation failed: {e}")The ImageService class defines four methods:
- create_image: uses the
ImageRepositoyto save images to the database. - generate_image: uses the OpenAI API and
dall-e-3to generate an image. It's wrapped by the tenacity decorator to perform exponential backoff and retry. The image generation API tends to be finicky, and requests are usually valid but must wait until OpenAI servers are ready to accept requests. Thus, we send an image generation request and wait a configurable amount before reattempting the request if errors arise. - generate_and_upload_image: This method calls the
generate_imageandupload_to_miniomethods to create an image based on the blog post and upload the generated image to Minio. - upload_to_minio: uploads files to Minio using the s3_client.
These layers of abstraction allow us to separate application logic from business (services) and data access (repositories). Allowing for easier maintenance and testing.
Docker Compose
We will run Postgres and Minio in Docker containers to experiment with them. Later in the series, I'll show my home lab setup, where I run Postgres in Kubernetes and Minio on my NAS (using TrueNAS applications).
version: "3"
services:
postgres:
image: postgres:16
hostname: postgres
ports:
- "5432:5432"
environment:
POSTGRES_USER: postgres-user # EXAMPLE ONLY CHANGE
POSTGRES_PASSWORD: postgres-pw #EXAMPLE ONLY CHANGE
POSTGRES_DB: demo
volumes:
- ./data:/var/lib/postgresql/data
- ./infrastructure/init-db.sh:/docker-entrypoint-initdb.d/init-db.sh:ro
minio:
image: quay.io/minio/minio
command: server /data --console-address :9001
restart: unless-stopped
ports:
- "9000:9000"
- "9001:9001"
environment:
MINIO_ACCESS_KEY: minioadmin # EXAMPLE CHANGE
MINIO_SECRET_KEY: minioadmin # EXAMPLE ONLY CHANGE
MINIO_ROOT_USER: minioadmin # EXAMPLE ONLY CHANGE
MINIO_ROOT_PASSWORD: minioadmin #EXAMPLE ONLY CHANGE
volumes:
- minio_data:/data
volumes:
pgdata:
minio_data:
For each service, we define:
- image: postgres16 | quay.io/minio/minio
- (optional) command
- ports
- environment: list of environment variables.
- volumes: used to persist data in the local directory
To start these containers, ensure you have the docker run time installed and run the following command:
docker-compose up -dThis will launch Postgres and Minio in the background.
You can check to ensure the services are running correctly using:
docker psLook for output similar to:

Summary
In this post, we enhanced our FastAPI application with real-time communication capabilities and improved data management. Key improvements include integrating WebSocket connections to stream progress events through a workflow. Introduced SQLAlchemy and Alembic for database interactions and migrations using Postgres. Expanded our code structure using Domain-Driven Design patterns, separating core and content functionality. Improved our dependency management with pyproject.toml and pip-tools.
What's Next
Thank you for tuning into part 3 of the GenAI Content Creator series. For part 4, we will add a user interface, allow users to interact with the workflow throughout its lifecycle, and update their content using a rich markdown editor.
Check out my GitHub for the complete implementation. I look forward to any feedback and discussions around AI/ML. I am currently a Software Architect at Groups360. Feel free to connect with me on LinkedIn.